-

关注我们
|
KMP算法看懂了就非常简单,但未理解之前确实非常晦涩,小编整理了对KMP算法的分析,希望能帮助到你^_^。  说明KMP算法求解字符串匹配问题。给你两个字符串,寻找其中一个字符串是否包含另一个字符串,如果包含,则返回包含的起始位置。 如下面两个字符串:
str有两处包含ptr,分别在str的下标10,26处包含ptr。 算法说明对于正常的字符串模式匹配,主串长度为m,子串为n,时间复杂度会到达O(m*n),而如果用KMP算法,复杂度将会减少线型时间O(m+n)。 为何简化了时间复杂度: 充分利用了目标字符串ptr的性质(比如里面部分字符串的重复性,即使不存在重复字段,在比较时,实现最大的移动量)。 考察目标字符串ptr: ababaca 这里我们要计算一个长度为m的转移函数next。 next[i](i从1开始算)代表着,除去第i个数,在一个字符串里面从第一个数到第(i-1)字符串前缀与后缀最长重复的个数。 什么是前缀? 在“aba”中,前缀就是“ab”,除去最后一个字符的剩余字符串。 同理可以理解后缀。除去第一个字符的后面全部的字符串。 在“aba”中,前缀是“ab”,后缀是“ba”,那么两者最长的子串就是“a”; 在“ababa”中,前缀是“abab”,后缀是“baba”,二者最长重复子串是“aba”; 在“abcabcdabc”中,前缀是“abcabcdab”,后缀是“bcabcdabc”,二者最长重复的子串是“abc”; 这里有一点要注意,前缀必须要从头开始算,后缀要从最后一个数开始算,中间截一段相同字符串是不行的。 比如aaaa相同的最长前缀和最长后缀是aaa。 对于目标字符串ptr,ababaca,长度是7,所以next[0],next[1],next[2],next[3],next[4],next[5],next[6]分别计算的是 a,ab,aba,abab,ababa,ababac,ababaca的相同的最长前缀和最长后缀的长度。由于a,ab,aba,abab,ababa,ababac,ababaca的相同的最长前缀和最长后缀是“”,“”,“a”,“ab”,“aba”,“”,“a”,所以next数组的值是[-1,-1,0,1,2,-1,0],这里-1表示不存在,0表示存在长度为1,2表示存在长度为3。这是为了和代码相对应。 代码解析void cal_next(char *str, int *next, int len){ next[0] = -1; //next[0]初始化为-1,-1表示不存在相同的最大前缀和最大后缀 int k = -1; for (int q = 1; q <= len-1; q++){ while (k > -1 && str[k + 1] != str[q]) //如果下一个不同,那么k就变成next[k],注意next[k]是小于k的,无论k取任何值。 { k = next[k];//往前回溯 } if (str[k + 1] == str[q]){ k = k + 1; } next[q] = k; //这个是把算的k的值(就是相同的最大前缀和最大后缀长)赋给next[q] }}KMPint KMP(char *str, int slen, char *ptr, int plen){ int *next = new int[plen]; cal_next(ptr, next, plen); int k = -1; for (int i = 0; i < slen; i++){ while (k >-1&& ptr[k + 1] != str[i]) //ptr和str不匹配,且k>-1(表示ptr和str有部分匹配) k = next[k];//往前回溯 if (ptr[k + 1] == str[i]) k = k + 1; if (k == plen-1) //说明k移动到ptr的最末端 { return i-plen+1; //返回相应的位置 } } return -1; }测试char *str = "bacbababadababacambabacaddababacasdsd"; char *ptr = "ababaca"; int a = KMP(str, 36, ptr, 7); return 0; 如果本文对您有用的话欢迎动动手指关注我们哦,以后还会发布更多有关计算机考研的知识分享,同时也欢迎同是计算机考研的童鞋私信我们呢~  |

近年来,随着高校毕业生人数连续增长,应届生就业难度越来越大。...详细
相信大部分的小伙伴考完第一件事就是估分,那么估分后如何知道自...详细

深圳大学举行了2021年奖学金颁奖典礼,副校长、相关部门学院负责...详细
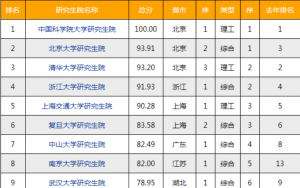
我国硕博点多如牛毛,研究生院也琳琅满目,那么究竟哪些高校的研...详细

